by blog_admin
Data Mining Research Guidance and Thesis Topics
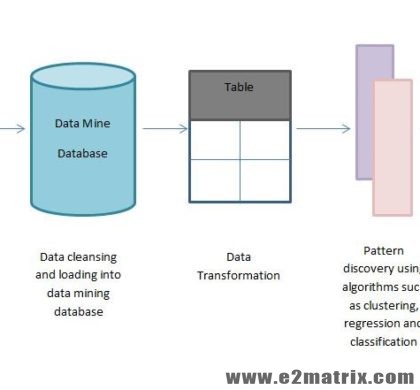
Data Mining Research Guidance The field of data mining and knowledge discovery has been attracting a significant amount of research attention. An enormous amount of data has been generated every day. Data are being collected and accumulated at a dramatic pace due to the rapidly growing volumes of digital data. Data mining is the process of extracting useful information, patterns or inferences from large data...
Read More
Feature Selection in Data Mining
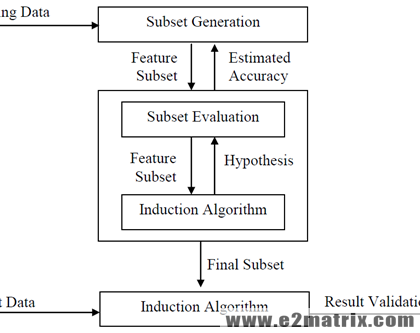
In Machine Learning and statistics, feature selection, also known as the variable selection is the operation of specifying a division of applicable features for apply in form of the model formation. The center basis after operating an element collection approach so as to the data hold a number attributes. It is an algorithm can be seen as the grouping of a search procedure for proposes original attribute subsets, along with...
Read More
Semi-Supervised Learning Models
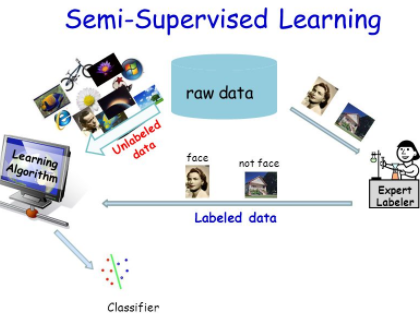
Semi-Supervised is a category of the Machine Learning approaches and create to control of labeled or unlabeled data for instructions, typically small number of labeled data within a long number of unlabeled data. Semi-Supervised learning fall between unsupervised and supervised knowledge. This approach can be used for traffic identification or classification. This capability suggests traffic classification methods. It depends on single precede information to order...
Read More
Machine Learning Techniques
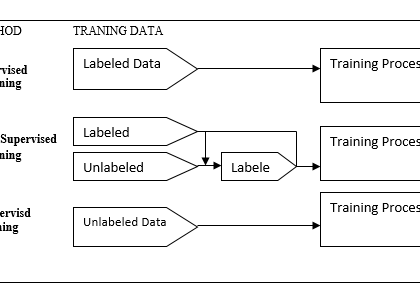
Machine learning focuses on calculations, based on known property learned from the training data. Representation of information instance and purpose evaluate on these instances are part of all machine learning systems. Overview of the assets that the system will perform well on unseen data instances; the situations under which this can be specific are an input object of learning in the subfield of computational learning...
Read More

Ensemble Learning approach in Data Mining
In our day to day life, when crucial decisions are made in a meeting, a voting among the members present in the meeting is conducted when the opinions of the members conflict with each other. This principle of “voting” can be applied to data mining also. In the voting scheme, when classifiers are combined, the class assigned to a test instance will be the one...
Read More
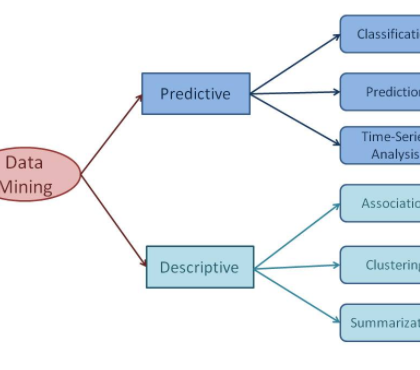
Classification in Data Mining
Classification is the process of finding a model (or function) that describes and distinguishes data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known). Classification predicts categorical (discrete,...
Read More
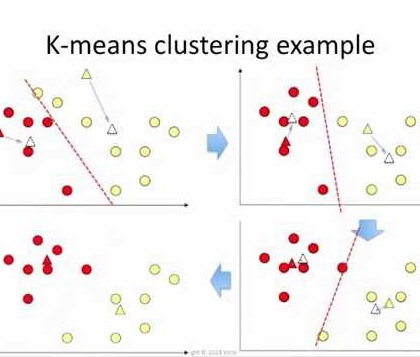
KMeans Clustering With Example
Clustering is the process of making a group of abstract objects into classes of similar objects. Having similarity inside clusters to be high and low clustering similarities between the clusters. A cluster of data objects can be treated as one group. While doing cluster analysis, we first partition the set of data into groups based on data similarity and then assign the labels to the...
Read More
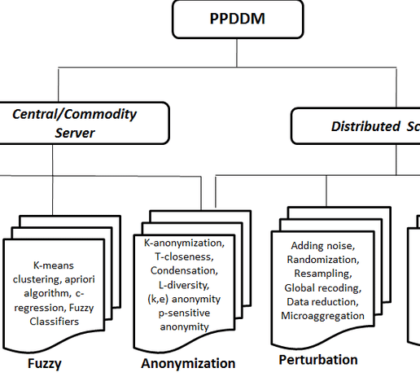
Privacy Preserving Data Mining (PPDM) Techniques
Based on the five dimensions explained in the previous blog different PPDM techniques can be categorized into following categories. PPDM is divided into two parts centralized and distributed which is further categorized into 5 techniques. 1. Anonymization Based: Anonymization is a technique in which record owner’s identity or sensitive data remain hidden. In a table, the most basic form of data consists of four types...
Read More