by blog_admin
Machine Learning Research Scientist and help in Vancouver | Surrey BC
Machine Learning is a “Field of study that gives computers the ability to learn without being explicitly programmed”. In this data driven age, machine learning is being used to compile and extract the massive volumes of data that are generated daily. Big shot multinational corporations are now using machine learning to glean real-time insights to enhance their business performance or gain an extra edge over...
Read More

by blog_admin
Machine Learning Projects for Students in Vancouver | Surrey BC
Making good project in Machine learning for students in Surrey, BC using Matlab is the one of the most difficult task for a students, because it involves very deep knowledge of machine learning. So our experts offer you best machine learning projects for students in Vancouver, BC by which you can get full guidance for your project submission. You not only get the particle but...
Read More

by blog_admin
Machine Learning Assignment Help in Vancouver | Surrey, BC
If you are student of university or collage? And struggling with your Assignment to complete and submitted on time? Then you are at the right place E2matrix is one of the best origination which provides you best Machine learning assignment help in Vancouver, BC at low cost. Projects submission is one of the most challenging Task give to student by their matter. But in today life...
Read More
by blog_admin
Latest Machine Learning Thesis Topics and Thesis Implementation
What is Machine Learning? Machine Learning is a “Field of study that gives computers the ability to learn without being explicitly programmed”. In this data-driven age, machine learning is being used to compile and extract the massive volumes of data that are generated daily. Big shot multinational corporations are now using machine learning to glean real-time insights to enhance their business performance or gain an...
Read More

by blog_admin
Best Readymade M.Tech Projects List For CSE and ECE
E2matrix is one of the best M.Tech/ Ph.D. Thesis guidance institute in Punjab (India). E2matrix offers academic M.Tech Projects List and Help service to students from a long time. We are the best service provider at Punjab and nearby states. At E2matrix Training and Research Institute we have developed thousands of projects in different programming languages for CSE and ECE students from last 5 years....
Read More
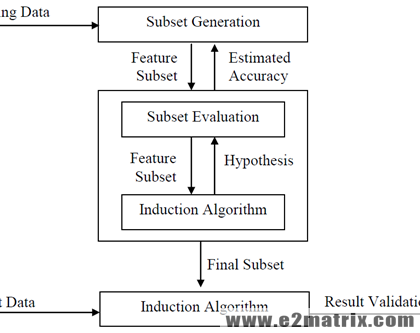
Feature Selection in Data Mining
In Machine Learning and statistics, feature selection, also known as the variable selection is the operation of specifying a division of applicable features for apply in form of the model formation. The center basis after operating an element collection approach so as to the data hold a number attributes. It is an algorithm can be seen as the grouping of a search procedure for proposes original attribute subsets, along with...
Read More
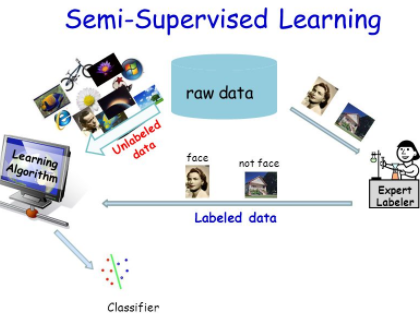
Semi-Supervised Learning Models
Semi-Supervised is a category of the Machine Learning approaches and create to control of labeled or unlabeled data for instructions, typically small number of labeled data within a long number of unlabeled data. Semi-Supervised learning fall between unsupervised and supervised knowledge. This approach can be used for traffic identification or classification. This capability suggests traffic classification methods. It depends on single precede information to order...
Read More

Ensemble Learning approach in Data Mining
In our day to day life, when crucial decisions are made in a meeting, a voting among the members present in the meeting is conducted when the opinions of the members conflict with each other. This principle of “voting” can be applied to data mining also. In the voting scheme, when classifiers are combined, the class assigned to a test instance will be the one...
Read More