Classification in Data Mining
Classification is the process of finding a model (or function) that describes and distinguishes data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known).
Classification predicts categorical (discrete, unordered) labels, prediction models continuous-valued functions. That is, it is used to predict missing or unavailable numerical data values rather than class labels.
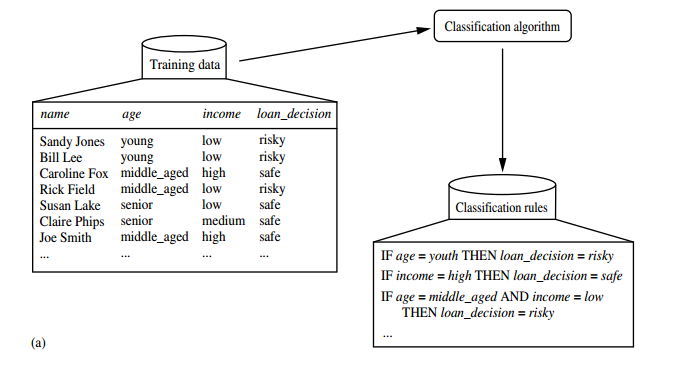
Data classification is a two-step process, as shown for the loan application data of Figure below. 1. In the first step, a classifier is built describing a predetermined set of data classes or concepts. This is the learning step (or training phase), where a classification algorithm builds the classifier by analysing or “learning from” a training set made up of database tuples and their associated class labels.
A tuple, X, is represented by an n-dimensional attribute vector, X = (x1 , x2, … , xn), depicting n measurements made on the tuple from n database attributes, respectively, A1 , A2, … , An.
Each tuple, X, is assumed to belong to a predefined class as determined by another database attribute called the class label attribute. The class label attribute is discrete-valued and unordered. It is categorical in that each value serves as a category or class. The individual tuples making up the training set are referred to as training tuples and are selected from the database under analysis. In the context of classification, data tuples can be referred to as samples, examples, instances, data points, or objects.
Because the class label of each training tuple is provided, this step is also known as
supervised learning (i.e., the learning of the classifier is “supervised” in that it is told to which class each training tuple belongs). It contrasts with unsupervised learning (or clustering), in which the class label of each training tuple is not known, and the number or set of classes to be learned may not be known in advance. For example, if we did not
have the loan decision data available for the training set, we could use clustering to try to determine “groups of like tuples,” which may correspond to risk groups within the loan application data.
This first step of the classification process can also be viewed as the learning of a mapping or function, y = f(X), that can predict the associated class label y of a given tuple X. In this view, we wish to learn a mapping or function that separates the data classes. Typically, this mapping is represented in the form of classification rules, decision trees, or mathematical formulae. In our example, the mapping is represented as classification rules that identify loan applications as being either safe or risky (Figure (a)). The rules can be used to categorize future data tuples, as well as provide deeper insight into the database contents. They also provide a compressed representation of the data.
“What about classification accuracy?” In the second step (Figure (b)), the model is used for classification. First, the predictive accuracy of the classifier is estimated. If we were to use the training set to measure the accuracy of the classifier, this estimate would likely be optimistic, because the classifier tends to overfit the data (i.e., during learning it may incorporate some particular anomalies of the training data that are not present in the general dataset overall). Therefore, a test set is used, made up of test tuples and their associated class labels. These tuples are randomly selected from the general data set. They are independent of the training tuples, meaning that they are not used to construct the classifier.
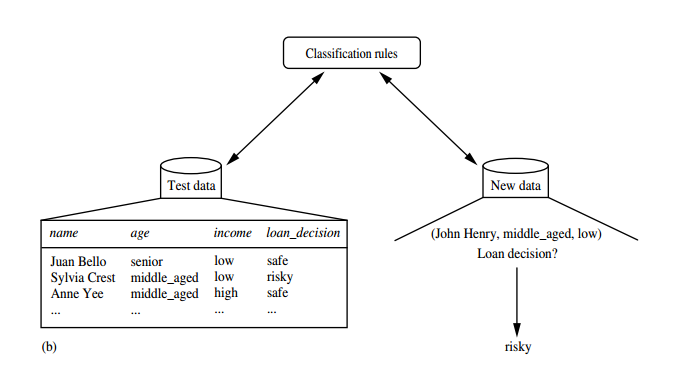
The accuracy of a classifier on a given test set is the percentage of test set tuples that are correctly classified by the classifier. The associated class label of each test tuple is compared with the learned classifier’s class prediction for that tuple If the accuracy of the classifier is considered acceptable, the classifier can be used to classify future data tuples for which the class label is not known. (Such data are also referred to in the machine learning literature as “unknown” or “previously unseen” data.) For example, the classification rules learned in Figure (a) from the analysis of data from previous loan applications can be used to approve or reject new or future loan applicants.
“How is (numeric) prediction different from classification?” Data prediction is a two-step process, similar to that of data classification as described in Figure above. However,
for prediction, we lose the terminology of “class label attribute” because the attribute
for which values are being predicted is continuous-valued (ordered) rather than categorical (discrete-valued and unordered). The attribute can be referred to simply as the
predicted attribute.3 Suppose that, in our example, we instead wanted to predict the
amount (in dollars) that would be “safe” for the bank to loan an applicant. The data
mining task becomes prediction, rather than classification. We would replace the categorical attribute, loan decision, with the continuous-valued loan amount as the predicted attribute, and build a predictor for our task. Note that prediction can also be viewed as a mapping or function, y = f(X), where X is the input (e.g., a tuple describing a loan applicant), and the output y is a continuous or ordered value (such as the predicted amount that the bank can safely loan the applicant); That is, we wish to learn a mapping or function that models the relationship between X and y
Steps to run the Classifier in weka
Step 1 Load The dataset
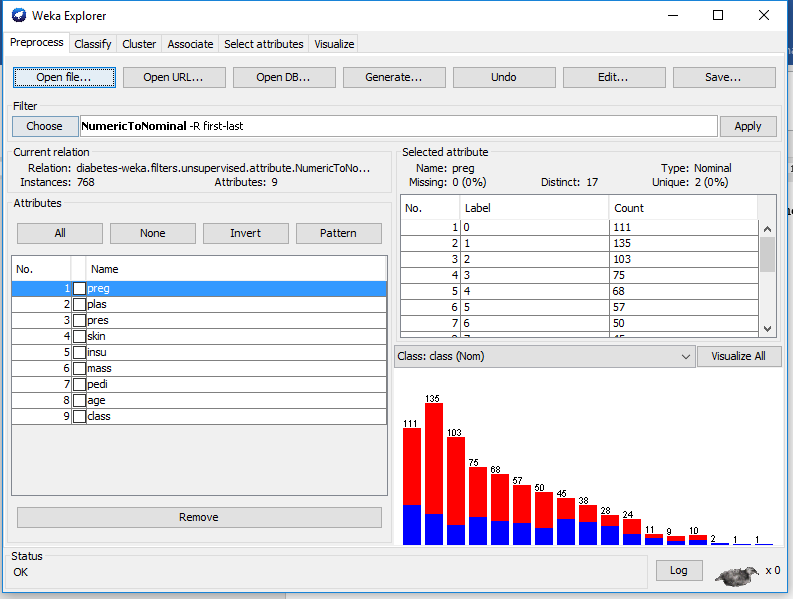
Step 2 Click to the classifier tab and choose the classifier
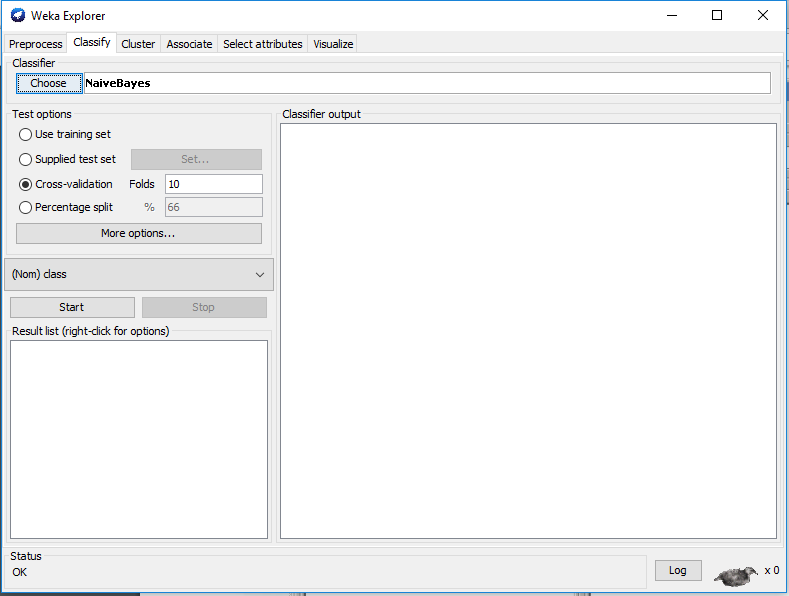
Step 3 Start the classifier and analyze the results
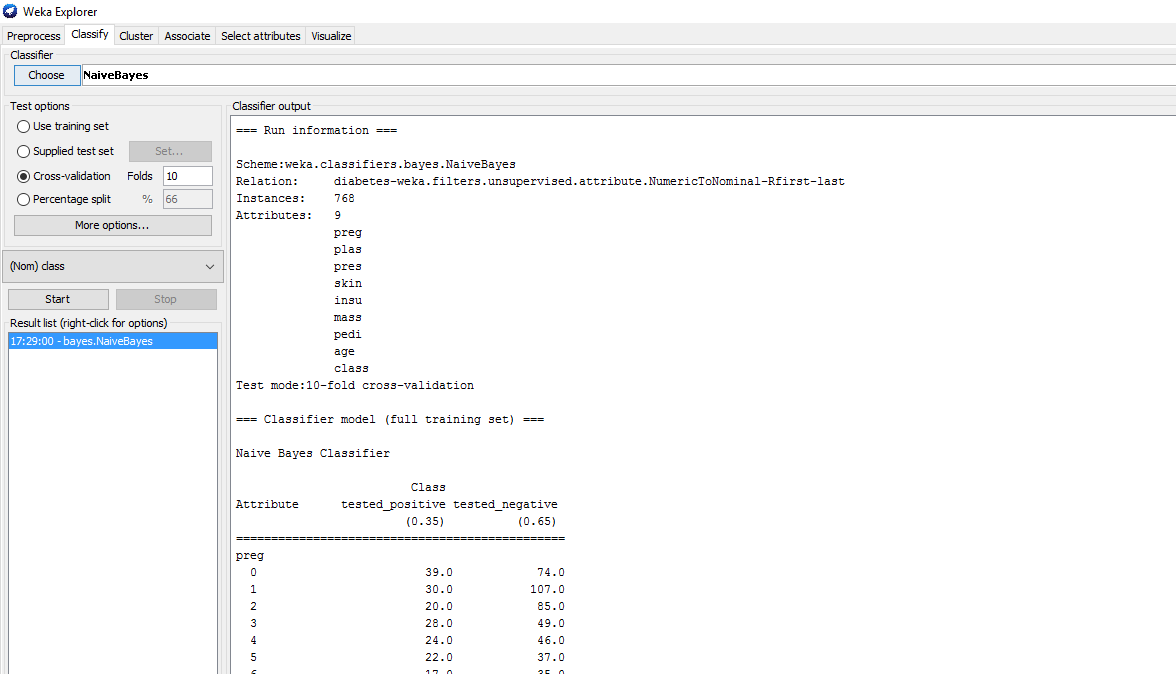
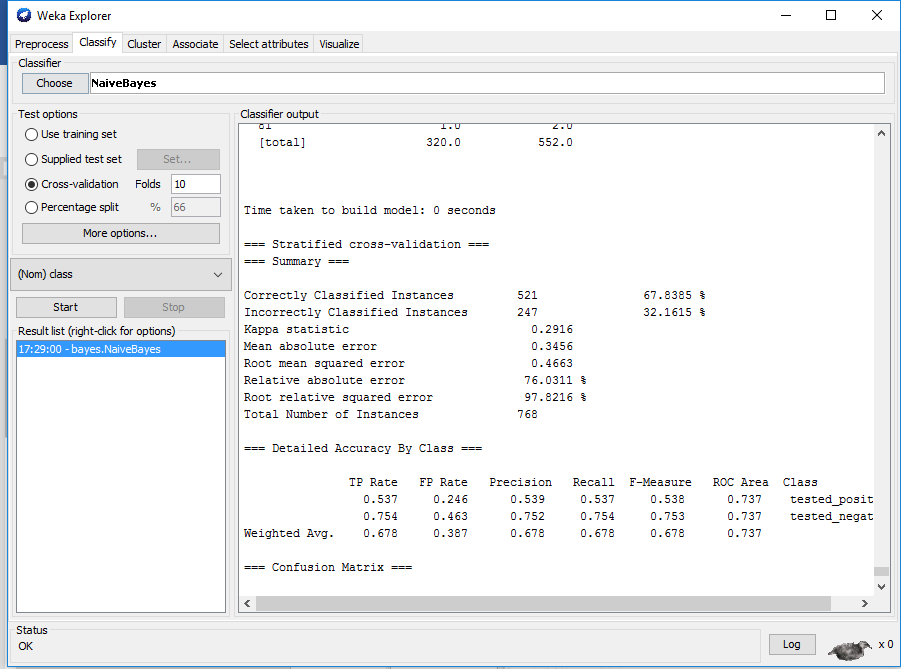
Recommended Posts
Data Mining Research Guidance and Thesis Topics
04 Jul 2018 - Data Mining
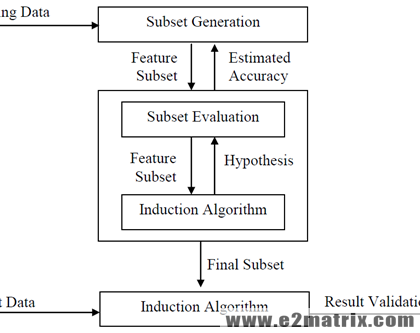
Feature Selection in Data Mining
06 Feb 2018 - Big Data, Data Mining, Machine Learning, Text Mining, Weka
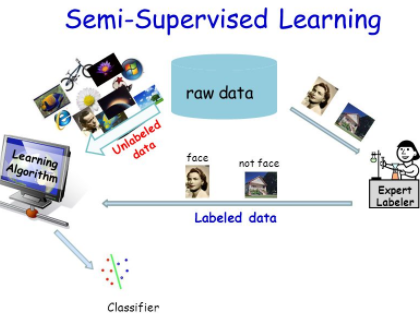
Semi-Supervised Learning Models
25 Jan 2018 - Data Mining, Machine Learning, Text Mining, Weka