
by Harleen Kaur
EEE topics for Mtech
Simulink, developed by maths Works, could be a graphical programming atmosphere for modelling, simulating and analysing multidomain dynamic systems. Its primary interface could be a graphical block diagram tool and a customize set of block libraries. It offers tight integration with the remainder of the MATLAB atmosphere and might either drive MATLAB or be scripted from it. Simulink is wide employed in automatic management and digital signal process for multi domain simulation and Model-Based style. 1.A Review on Current Reference Calculation of Three-Phase Grid-Connected PV Converters under Grid Faults 2.Six-Leg...
Read More
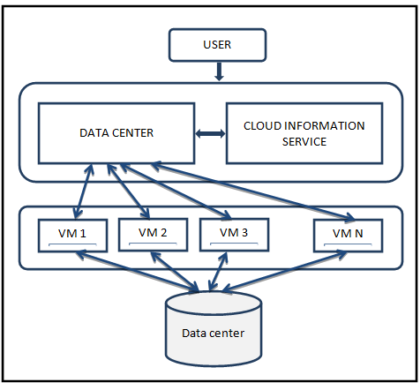
SCHEDULING IN CLOUD COMPUTING
In Cloud Computing, booking assumes a fundamental part in productively dealing with the PC administrations; it is the movement of enrapturing choices in regards to the allotment of accessible limit and/or assets to employment and/or clients on time. A large number of clients offer cloud administrations by presenting their a great many processing errands to the cloud computing environment. Booking of these a large number...
Read More

by Harleen Kaur
Latest Digital Image Processing Topics for Mtech
Visible watermark removal scheme based on reversible data hiding andimage inpainting,2017,Signal Processing: Image Communication Adaptive Scale Selection for Multiscale Segmentation of Satellite Images, 2017, IEEE JOURNAL A Novel Fuzzy Based Satellite Image Enhancement, 2017, Springer Science Fast uniform content-based satellite image registration using the scale-invariant feature transform descriptor, 2017, Frontiers of Information Technology & Electronic Engineering Enhancement of Satellite Image Compression Using a Hybrid (DWT–DCT)...
Read More
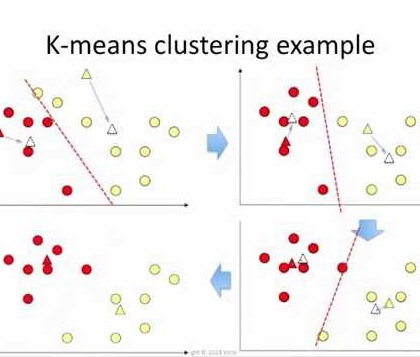
KMeans Clustering With Example
Clustering is the process of making a group of abstract objects into classes of similar objects. Having similarity inside clusters to be high and low clustering similarities between the clusters. A cluster of data objects can be treated as one group. While doing cluster analysis, we first partition the set of data into groups based on data similarity and then assign the labels to the...
Read More