How to prepare dataset in arff and csv format
Machine learning algorithms are primarily designed to work with arrays of numbers.
This is called tabular or structured data because it is how data looks in a spreadsheet, comprised of rows and columns.
Weka has a specific computer science centric vocabulary when describing data:
- Instance: A row of data is called an instance, as in an instance or observation from the problem domain.
- Attribute: A column of data is called a feature or attribute, as in feature of the observation.
Each attribute can have a different type, for example:
- Real for numeric values like 1.2.
- Integer for numeric values without a fractional part like 5.
- Nominal for categorical data like “dog” and “cat”.
- Stringfor lists of words, like this sentence.
Data in Weka
Weka prefers to load data in the ARFF format.
ARFF is an acronym that stands for Attribute-Relation File Format. It is an extension of the CSV file format where a header is used that provides metadata about the data types in the columns.
For example, the first few lines of the classic iris flowers dataset in CSV format looks as follows:
| 1. 5.1,3.5,1.4,0.2,Iris-setosa
2. 4.9,3.0,1.4,0.2,Iris-setosa 3. 4.7,3.2,1.3,0.2,Iris-setosa 4. 4.6,3.1,1.5,0.2,Iris-setosa 5. 5.0,3.6,1.4,0.2,Iris-setosa |
The same file in ARFF format looks as follows:
| 1
2 3 4 5 6 7 8 9 10 11 12 |
@RELATION iris
@ATTRIBUTE sepallength REAL @ATTRIBUTE sepalwidth REAL @ATTRIBUTE petallength REAL @ATTRIBUTE petalwidth REAL @ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica} @DATA 5.1,3.5,1.4,0.2, Iris-setosa 4.9,3.0,1.4,0.2, Iris-setosa 4.7,3.2,1.3,0.2, Iris-setosa 4.6,3.1,1.5,0.2, Iris-setosa 5.0,3.6,1.4,0.2, Iris-setosa |
More details of ARFF File Format
ARFF files have two distinct sections. The first section is the Header information, which is followed the Data information.
The Header of the ARFF file contains the name of the relation, a list of the attributes (the columns in the data), and their types. An example header on the standard IRIS dataset looks like this:
% 1. Title: Iris Plants Database % % 2. Sources: % (a) Creator: R.A. Fisher % (b) Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov) % (c) Date: July, 1988 % @RELATION iris @ATTRIBUTE sepallength NUMERIC @ATTRIBUTE sepalwidth NUMERIC @ATTRIBUTE petallength NUMERIC @ATTRIBUTE petalwidth NUMERIC @ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
The Data of the ARFF file looks like the following:
@DATA 5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa 4.7,3.2,1.3,0.2,Iris-setosa 4.6,3.1,1.5,0.2,Iris-setosa 5.0,3.6,1.4,0.2,Iris-setosa 5.4,3.9,1.7,0.4,Iris-setosa 4.6,3.4,1.4,0.3,Iris-setosa 5.0,3.4,1.5,0.2,Iris-setosa 4.4,2.9,1.4,0.2,Iris-setosa 4.9,3.1,1.5,0.1,Iris-setosa
Lines that begin with a % are comments.
The @RELATION, @ATTRIBUTE and @DATA declarations are case insensitive.
Examples
Several well-known machine learning datasets are distributed with Weka in the $WEKAHOME/data directory as ARFF files.
The ARFF Header Section
The ARFF Header section of the file contains the relation declaration and attribute declarations.
The @relation Declaration
The relation name is defined as the first line in the ARFF file. The format is:
@relation <relation-name>
where <relation-name> is a string. The string must be quoted if the name includes spaces.
The @attribute Declarations
Attribute declarations take the form of an ordered sequence of @attribute statements. Each attribute in the data set has its own @attribute statement which uniquely defines the name of that attribute and it’s data type. The order the attributes are declared indicates the column position in the data section of the file. For example, if an attribute is the third one declared then Weka expects that all that attributes values will be found in the third comma delimited column.
The format for the @attribute statement is:
@attribute <attribute-name> <datatype>
where the <attribute-name> must start with an alphabetic character. If spaces are to be included in the name then the entire name must be quoted.
The <datatype> can be any of the four types currently supported by Weka:
- numeric
- <nominal-specification>
- string
- date [<date-format>]
where <nominal-specification> and <date-format> are defined below. The keywords numeric, string and date are case insensitive.
Numeric attributes
Numeric attributes can be real or integer numbers.
Nominal attributes
Nominal values are defined by providing an <nominal-specification> listing the possible values: {<nominal-name1>, <nominal-name2>, <nominal-name3>, …}
For example, the class value of the Iris dataset can be defined as follows:
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
Values that contain spaces must be quoted.
String attributes
String attributes allow us to create attributes containing arbitrary textual values. This is very useful in text-mining applications, as we can create datasets with string attributes, then write Weka Filters to manipulate strings (like StringToWordVectorFilter). String attributes are declared as follows:
@ATTRIBUTE LCC string
Date attributes
Date attribute declarations take the form:
@attribute <name> date [<date-format>]
where <name> is the name for the attribute and <date-format> is an optional string specifying how date values should be parsed and printed (this is the same format used by SimpleDateFormat). The default format string accepts the ISO-8601 combined date and time format: “yyyy-MM-dd’T’HH:mm:ss“.
Dates must be specified in the data section as the corresponding string representations of the date/time (see example below).
ARFF Data Section
The ARFF Data section of the file contains the data declaration line and the actual instance lines.
The @data Declaration
The @data declaration is a single line denoting the start of the data segment in the file. The format is:
@data
The instance data
Each instance is represented on a single line, with carriage returns denoting the end of the instance.
Attribute values for each instance are delimited by commas. They must appear in the order that they were declared in the header section (i.e. the data corresponding to the nth @attribute declaration is always the nth field of the attribute).
Missing values are represented by a single question mark, as in:
@data 4.4,?,1.5,?,Iris-setosa
Values of string and nominal attributes are case sensitive, and any that contain space must be quoted, as follows:
@relation LCCvsLCSH @attribute LCC string @attribute LCSH string @data AG5, ‘Encyclopedias and dictionaries.;Twentieth century.’ AS262, ‘Science — Soviet Union — History.’ AE5, ‘Encyclopedias and dictionaries.’ AS281, ‘Astronomy, Assyro-Babylonian.;Moon — Phases.’ AS281, ‘Astronomy, Assyro-Babylonian.;Moon — Tables.’
Dates must be specified in the data section using the string representation specified in the attribute declaration. For example:
@RELATION Timestamps @ATTRIBUTE timestamp DATE “yyyy-MM-dd HH:mm:ss” @DATA “2001-04-03 12:12:12” “2001-05-03 12:59:55”
Conversion of CSV file Forma into ARFF File Format
Your data is not likely to be in ARFF format.
In fact, it is much more likely to be in Comma Separated Value (CSV) format. This is a simple format where data is laid out in a table of rows and columns and a comma is used to separate the values on a row. Quotes may also be used to surround values, especially if the data contains strings of text with spaces.
The CSV format is easily exported from Microsoft Excel, so once you can get your data into Excel, you can easily convert it to CSV format.
Weka provides a handy tool to load CSV files and save them in ARFF. You only need to do this once with your dataset.
Using the steps below you can convert your dataset from CSV format to ARFF format and use it with the Weka workbench. If you do not have a CSV file handy, you can use the iris flowers dataset. Download the file from the UCI Machine Learning repository (direct link) and save it to your current working directory as iris.csv.
- Start the Weka chooser

Screenshot of the Weka GUI Chooser
- Open the ARFF-Viewer by clicking “Tools” in the menu and select “ArffViewer”.
- You will be presented with an empty ARFF-Viewer window
- Open your CSV file in the ARFF-Viewer by clicking the “File” menu and select “Open”. Navigate to your current working directory. Change the “Files of Type:” filter to “CSV data files (*.csv)”. Select your file and click the “Open” button.
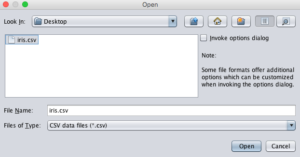
Load CSV In ARFF Viewer
- You should see a sample of your CSV file loaded into the ARFF-Viewer.
- Save your dataset in ARFF format by clicking the “File” menu and selecting “Save as…”. Enter a filename with a .arff extension and click the “Save” button.
You can now load your saved .arff file directly into Weka.
Note, the ARFF-Viewer provides options for modifying your dataset before saving. For example you can change values, change the name of attributes and change their data types.
It is highly recommended that you specify the names of each attribute as this will help with analysis of your data later. Also, make sure that the data types of each attribute are correct.
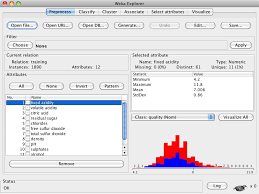
Load CSV Files in the Weka Explorer
You can also load your CSV files directly in the Weka Explorer interface.
This is handy if you are in a hurry and want to quickly test out an idea.
This section shows you how you can load your CSV file in the Weka Explorer interface. You can use the iris dataset again, to practice if you do not have a CSV dataset to load.
- Start the Weka GUI Chooser.
- Launch the Weka Explorer by clicking the “Explorer” button.
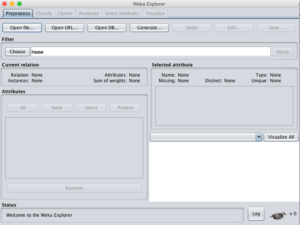
Screenshot of the Weka Explorer
- Click the “Open file…” button.
- Navigate to your current working directory. Change the “Files of Type” to “CSV data files (*.csv)”. Select your file and click the “Open” button.
You can work with the data directly. You can also save your dataset in ARFF format by clicking he “Save” button and typing a filename.
Recommended Posts
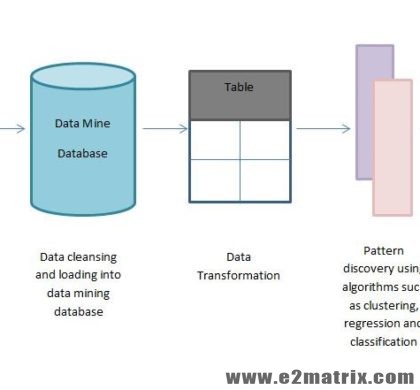
Data Mining Research Guidance and Thesis Topics
04 Jul 2018 - Data Mining
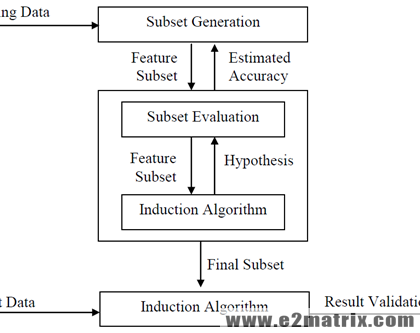
Feature Selection in Data Mining
06 Feb 2018 - Big Data, Data Mining, Machine Learning, Text Mining, Weka
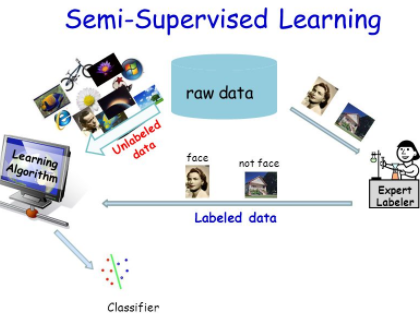
Semi-Supervised Learning Models
25 Jan 2018 - Data Mining, Machine Learning, Text Mining, Weka