Privacy Preserving Data Mining
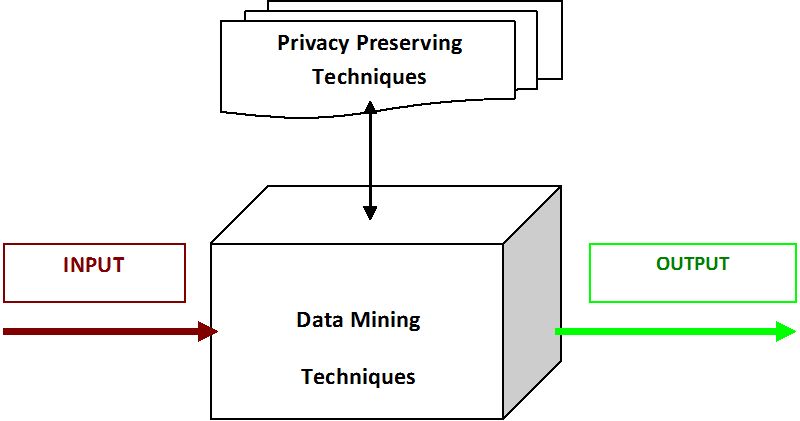
Data mining is one of the rapidly increasing fields in the computer industry that deals with extracting patterns from large data sets. It is used to extract human understandable information. Moreover, data mining plays an important role in many business organizations, financial, educational and health companies and revealing sensitive information is a big harm. From the point of view of the organization, mining is helpful for their future sales; attackers also use raw computing to hack the database which includes individual’s personal information. Thus, there is need to prevent disclosure of private information and also know which is considered to be sensitive in any given context. Due to this, many efforts have been devoted to addressing the issue of privacy preserving in data mining. As a result, several data mining algorithms incorporate with privacy-preserving techniques has been developed.
Since its commencement in 2000 with the work of Agrawal & Srikant and Lindell & Pinkas, privacy preserving data mining has attained popularity in the data mining research community.
PPDM has become one of the main issues in data mining.PPDM research methods focused on various algorithms such as clustering algorithm, classification mining algorithm, association rule mining and so on. Many algorithms developed based on encryption methods such as association rule mined on horizontal and vertically partitioned data, clustering mining, association mining etc. Taxonomy of these algorithms is there i.e. how these algorithms are divided.
Moreover, identify following the set of criteria based on which PPDM algorithms can be evaluated:
- Privacy level provided by a privacy-preserving technique, which indicates the sensitive information that has been unseen, can still be evaluated.
- Complexity, that is, the potential of a privacy-preserving algorithm to implemented with fine performance in terms of all the resources implied by the algorithm.
- Information Loss is generally proportional to the level of security and the sum of noise added. It is inversely proportional to the quality of data. The key requirement of the privacy-preserving technique is to retain high data quality in released data sets. Maintaining high security will be useless if data quality is not kept.
- Cost refers to both communication cost and computation cost between the associating parties.
PPDM dimensions/methods on which PPDM techniques can be classified:
- Data distribution
- Data distortion/modification
- Data mining algorithms
- Data hiding
- Privacy preservation.
Distribution of data: Currently, some approaches have been executed for centralized data, while other on distributed data. The dataset which is placed centralized is possessed by an individual party. However, two or more parties shared the distributed datasets which do not trust each other personal data but keen to execute data mining on joint data. Distributed data scenarios consist of horizontal and vertical data. Horizontal distribution refers to cases where different records reside in different sites and vertical distribution refers to cases where all values for different attributes reside in different places.
Modification of data: This method is used to modify the original values before release so that privacy should be achieved. Modification methods include perturbation, blocking, aggregation, merging, swapping and sampling. All these methods are accomplished by transforming the granularity of an attribute value.
Data mining algorithm: The Third dimension is data mining algorithms which are applied to transform data to get the useful lump of information that was hidden previously. The mining algorithms include classification mining, association rule mining, clustering, and Bayesian networks etc.
Data hiding: Data hiding describes to the type in which sensitive information like name, identity, and address from the original dataset that can be linked, directly or indirectly, to an individual person are hidden.
Privacy preservation: It refers to the techniques that are actually used to protect privacy. And in order to preserve privacy, data modification should be done carefully so as to achieve high data utility.