Hadoop Introduction
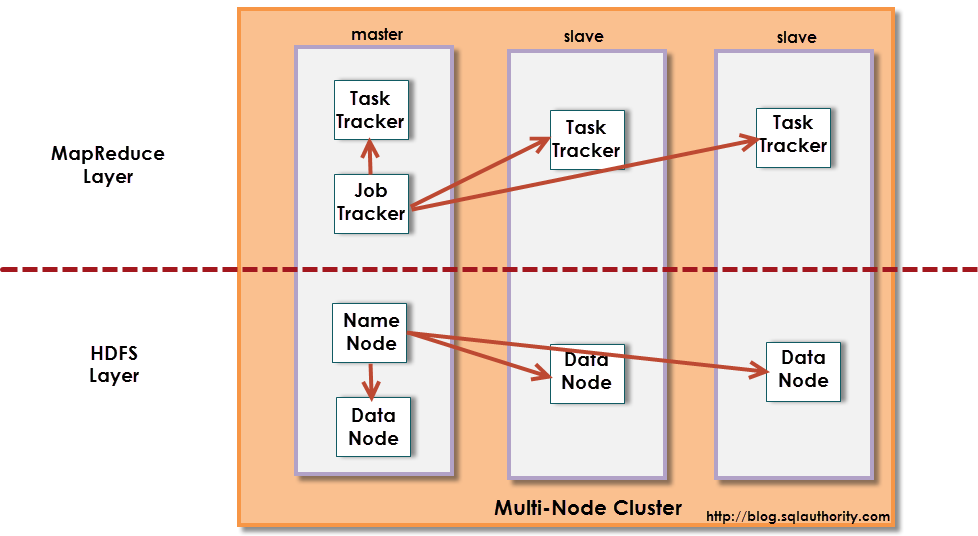
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject.
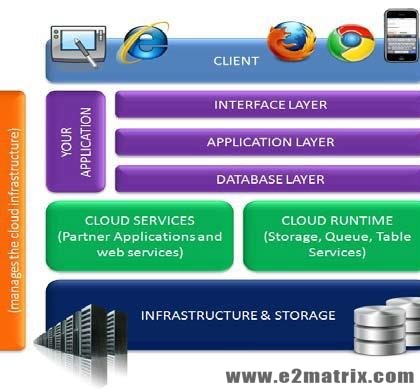
Apache Hadoop is a framework that allows for distributed processing of large data sets across clusters of commodity computers using a simple programming model. It is used as a Processing Platform for Big Data processing by using the “Map Reduce” Processing Paradigm.
Characteristics:
– Open Source
– Commodity Hardware based
– Highly Scalable
– Reliability provided through replication
Hadoop core components
- HDFS (Hadoop Distributed File System) – Storage
- Map Reduce Engine – Processing

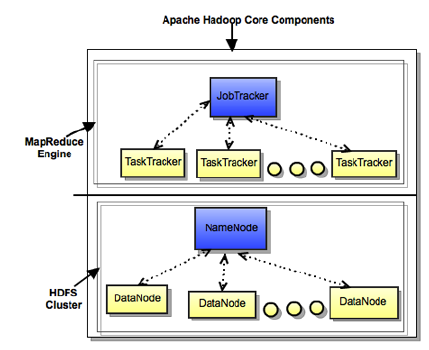

Hadoop Cluster Modes
- Pseudo Mode :
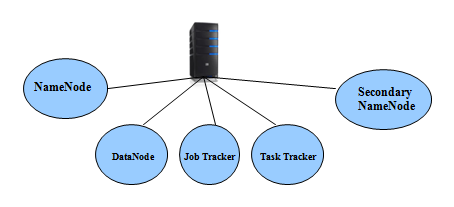
Note: All daemons run on same machine i.e storage and processing happens on the same machine.
- Distributed Mode:

Note: Daemons run on different machine i.e storage and processing happens on different machine.