Hadoop and Word Count | Hadoop Distributed File System
Hadoop is an Apache open source framework written in Java that allows distributed processing of large datasets across clusters of computers using simple programming models. A Hadoop frame-worked application works in an environment that provides distributed storage and computation across clusters of computers. Hadoop is designed to scale up from a single server to thousands of machines, each offering local computation and storage.
Hadoop Architecture
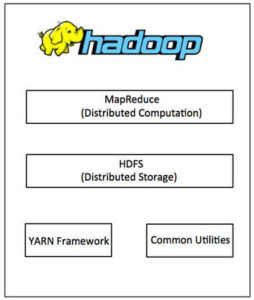
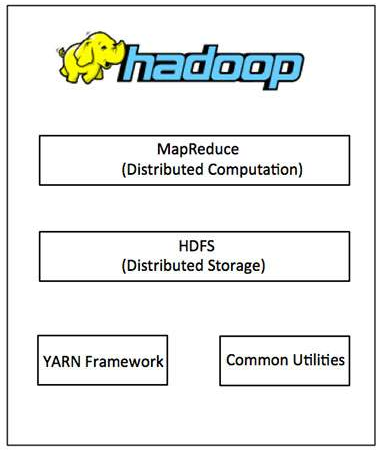
Hadoop framework includes following four modules:
- Hadoop Common: These are Java libraries and utilities required by other Hadoop modules. These libraries provide filesystem and OS level abstractions and contain the necessary Java files and scripts required to start Hadoop.
- Hadoop YARN: This is a framework for job scheduling and cluster resource management.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop MapReduce: This is a YARN-based system for parallel processing of large datasets.
We can use the following diagram to depict these four components available in Hadoop framework.
Since 2012, the term “Hadoop” often refers not just to the base modules mentioned above but also to the collection of additional software packages that can be installed on top of or alongside Hadoop, such as Apache Pig, Apache Hive, Apache HBase, Apache Spark etc.
MapReduce
Hadoop MapReduce is a software framework for easily writing applications which process big amounts of data in parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
The term MapReduce actually refers to the following two different tasks that Hadoop programs perform:
- The Map Task: This is the first task, which takes input data and converts it into a set of data, where individual elements are broken down into tuples (key/value pairs).
- The Reduce Task: This task takes the output from a map task as input and combines those data tuples into a smaller set of tuples. The reduce task is always performed after the map task.
Typically both the input and the output are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
The MapReduce framework consists of a single master JobTracker and one slaveTaskTracker per cluster-node. The master is responsible for resource management, tracking resource consumption/availability and scheduling the jobs component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves TaskTracker execute the tasks as directed by the master and provide task-status information to the master periodically.
The JobTracker is a single point of failure for the Hadoop MapReduce service which means if JobTracker goes down, all running jobs are halted.
Hadoop Distributed File System
Hadoop can work directly with any mountable distributed file system such as Local FS, HFTP FS, S3 FS, and others, but the most common file system used by Hadoop is the Hadoop Distributed File System (HDFS).
The Hadoop Distributed File System (HDFS) is based on the Google File System (GFS) and provides a distributed file system that is designed to run on large clusters (thousands of computers) of small computer machines in a reliable, fault-tolerant manner.
HDFS uses a master/slave architecture where master consists of a single NameNode that manages the file system metadata and one or more slave DataNodes that store the actual data.
A file in an HDFS namespace is split into several blocks and those blocks are stored in a set of DataNodes. The NameNode determines the mapping of blocks to the DataNodes. The DataNodes takes care of reading and writes operation with the file system. They also take care of block creation, deletion, and replication based on an instruction given by NameNode.
HDFS provides a shell like any other file system and a list of commands are available to interact with the file system. These shell commands will be covered in a separate chapter along with appropriate examples.
Working with Hadoop
Stage 1
A user/application can submit a job to the Hadoop (a Hadoop job client) for a required process by specifying the following items:
- The location of the input and output files in the distributed file system.
- The java classes in the form of jar file containing the implementation of a map and reduce functions.
- The job configuration by setting different parameters specific to the job.
Stage 2
The Hadoop job client then submits the job (jar/executable etc) and configuration to the JobTracker which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Stage 3
The TaskTrackers on different nodes execute the task as per MapReduce implementation and output of the reduce function is stored into the output files on the file system.
WHAT IS WORD COUNT
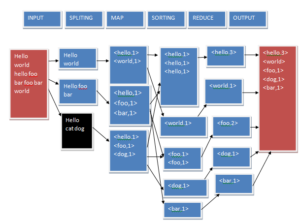
Word count is a typical problem which works on Hadoop distributed file system and map reduce is an intended count the no. of occurrence of each word in the provided input file. Word count operation takes places in two phases:-
- Mapper phase: In this phase first the text is tokenized into word then we form a key-value pair with these words where the key is the word itself and value ‘1’. Mapper class executes completely on the entire data set splitting the word and forming the initial key value pair. Only after this entire process is completed the reducer start.
- Reducer phase: In reduce phase the key are grouped together and the value for similar keys are added. This could give the no of occurrence of each word in the input file. It creates an aggregation phase for the key.
MAP REDUCE ALGORITHM
- Map reduce is a programming model and it is designed to compute the large volume of data in a parallel fashion.
- Map operation is written by user in which takes a set of input key/values pairs and produces a set of intermediate key #1
- Reduce function also written by the user, accept an intermediate key #1 and a set of value for that key .it merges together these values to form a possibly smaller set of value.
- Map reduce operations are carried out in Hadoop.
- Hadoop is a distributed sorting
Map and reduce in word count problem Algorithm
mapper(file name , file-count);
for each word in file-contents;
emit(word,1)
reducer (word, value);
sum=0
for each value in values
sum=sum + value
emit(word , sum)
DATA FLOW DIAGRAM
METHODOLOGY
Map reduce is a 3 steps approach to solving a problem:-
Step 1:- Map
The purpose of a map step is to group or divide data into a set based on desired value. While using map function we need to be careful about 3 things.
- How do we want to divide or group the data?
- Which part of the data we need or which part of the data is extraneous?
- In what form or structure do we need our data?
Step 2:- Reduce
Reduce operation combine different values for each given key using a user-defined function. Reduce operation will take up each key and pick up all the values created from map step and process them one by one using custom define logic. It will take 2 parameters:-
- Key
- Array of values
Step 3:-Finalized
It is used to do any required transformation on the final output of the reduce.
FUTURE SCOPE
It is used in many applications because of parallel processing like document clustering, web link graph reversing and inverted index construction. As it is map-reduce so it increases the efficiency of handling big data .it is used where we need data to be available all the times and security is needed.map reduce related works are:-
- Yahoo!: Web map application uses Hadoop to create a database of information on all known webpage.
- Facebook: Hadoop provides Hive data center.
- Backspace: It analyzes server log files and usage data using Hadoop.
Visitor Rating: 5 Stars