Data Mining
In the field of Information technology, we have a huge amount of data available that need to be turned into useful information.
Major sources of abundant data
- Business: Web, e-commerce, transactions, stocks,…
- Science: Remote sensing, bioinformatics, scientific simulation, …
- Society and everyone: news, digital cameras, YouTube
 We are data rich, but information poor
We are data rich, but information poor
Data mining
Data Mining is defined as extracting the information from the huge set of data. In other words, we can say that data mining is mining the knowledge from data.
Data mining—searching for knowledge (interesting patterns) in your data
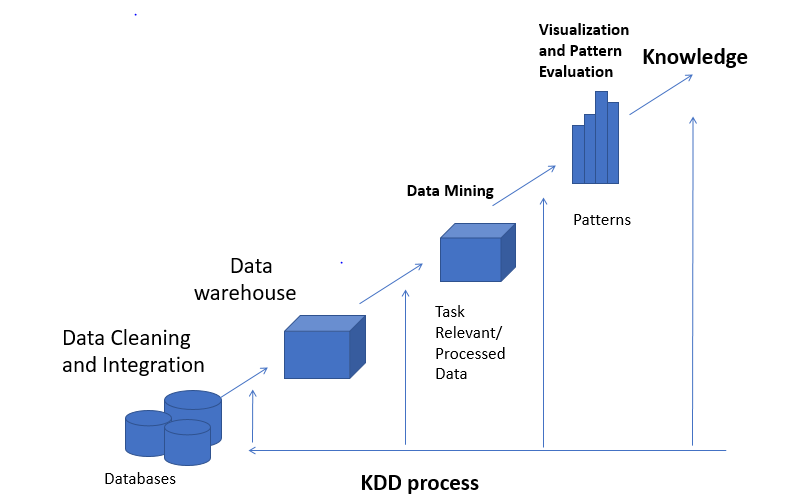
Data Mining Process

1. Data cleaning (to remove noise and inconsistent data)
2. Data integration (where multiple data sources may be combined)
3. Data selection(where data relevant to the analysis task are retrieved from the database)
4. Data transformation(where data are transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations, for instance)2
5. Data mining (an essential process where intelligent methods are applied in order to extract data patterns)
6. Pattern evaluation (to identify the truly interesting patterns representing knowledge based on some interesting measures)
7. Knowledge presentation (where visualization and knowledge representation techniques are used to present the mined knowledge to the user)
Applications of Data mining
This extracted information further can be used for various applications such as
- Market analysis
- Fraud detection
- Predict customer defections
- Medical field
- social media analysis etc.
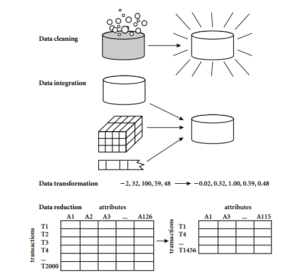
Data Mining Phases(1): Pre-Processing
Need of Data Pre-processing
Today’s real-world databases are highly susceptible to noisy, missing, and inconsistent data due to their typically huge size (often several gigabytes or more) and their likely origin from multiple, heterogeneous sources.
Low-quality data will lead to low-quality mining results
Stages in Pre-Processing
Data Mining Functionalities (1)
Classification
It is the process of generating a model that can be used to predict the class of unknown data object. The derived model is based on the analysis of a set of training data (i.e., data objects whose class label is known).
It is a supervised technique.
Some common techniques used in Classification
Decision Tree
- A decision tree is a flow-chart-like tree structure, where each node denotes a test on an attribute value, each branch represents an outcome of the test, and tree leaves represent classes or class distributions
Neural Network
- A neural network, when used for classification, is typically a collection of neuron-like processing units with weighted connections between the units.
There are many other methods for constructing classification models, such as naïve
Bayesian classification, support vector machines, and k-nearest neighbor classification.
Data Mining Functionalities (2)
Clustering
Clustering analyses data objects without consulting a known class label.
In general, the class labels are not present in the training data. Clustering can be used to generate such labels.
Some common techniques used are:
- K-means Clustering
- Hierarchical Clustering
Data Mining Functionalities (3)
Frequent Pattern Mining and Association Rule Mining
- Frequent patterns, as the name suggests, are patterns that occur frequently in data. There are many kinds of frequent patterns, including itemsets, subsequences, and substructures.
- A frequent itemset typically refers to a set of items that frequently appear together in a transactional data set, such as milk and bread in the market.
An example of a rule, mined from the Market database, is
buys(X, “Milk”) ⇒ buys(X, “Bread”) [support= 1%, confidence = 50%]
Recommended Posts
Data Mining Research Guidance and Thesis Topics
04 Jul 2018 - Data Mining
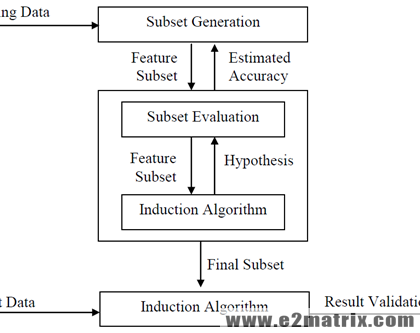
Feature Selection in Data Mining
06 Feb 2018 - Big Data, Data Mining, Machine Learning, Text Mining, Weka
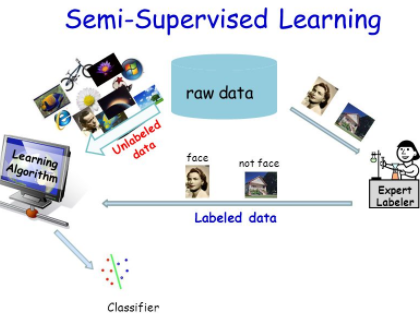
Semi-Supervised Learning Models
25 Jan 2018 - Data Mining, Machine Learning, Text Mining, Weka